Introduction
I’ve seen many websites like this one or that one talking about the most common unisex names or how to choose a cool unisex name for your baby, but I don’t know those so-called unisex names are based on what criteria and the authors there don’t say how they got them in the first place. In this article, I present a systematic way to get unisex names based on historical data of used baby names as far back as the year 1880. This article you are reading will go into the detailed analysis process, if you are not interested or you don’t care about the how-to, you can just jump to the results in Top 20 Unisex Names vs. Gender as I show the final unisex names with their distribution over both genders.

How do we define a unisex name?
If I ask you what makes a name “unisex”, you might say, “Unisex names are those which can be used on a boy or a girl” or “those which I would not be at all surprised whether I hear they’re being used for a boy or a girl”. Here we see the second definition to be a subjective one because an unusual name for some gender might surprise you but could be very natural and even cool for the same gender, for someone else. So we revert back to the first definition but if a name is mostly used for a girl and very rarely used for a boy, will we consider that a unisex name? I don’t support that idea, we need some measure of commonality of the name over both genders. Why not we consult data of baby names? This is something historical and it is an objective measure as it represents the collective view of people to different names. The prevalence of some gender over some name should negate that name’s “unisex” flag. Let’s say we define the middle third (33.3%-66.6%) as our threshold, so if a name is used on, let’s say girls, more than two thirds, we call the name female-dominant. If it is used on less than one third, then we call that name “male-dominant” name. Otherwise, we are left with the middle third which I propose to consider “unisex” names. I will get back to this point in the Analysis section.
Tools Used for This Analysis
In this data analysis I will use:
Python v2.7.
Numpy v1.9.2.
Pandas v0.16.2, and
Matplotlib v1.4.2.
Python and its companion libraries comprise a handy and flexible tool for data analysis. That makes you focus on researching/investigating the use case instead of getting lost in the technical details of programming.
Data
The data I will use for this analysis is published by the United States Social Security Administration. The data cover the historical period between 1880 and 2010. The total names count under this dataset is approximately 322 million (exactly 322,402,727) names. For privacy considerations, a particular name must have at least 5 occurrences to be included in the data.
Understanding Data
Let’s take a closer look at the data, we have 131 plain text files (one for each year from the year 1880 to the year 2010). Each file contains unique (name-sex) records with the corresponding number of births of that name for that gender. That means you could find the name to be duplicated (or not, as some names are truly gender-specific). If you check the raw structure of the files, they are actually CSV (comma-separated values) files and that’s how we will read them into our Python Pandas data structures.
Few points worth mentioning about the data:
- If a name doesn’t exist in some year (file), it doesn’t exist as a record in that year’s file (You never find a name lingering there with 0 births!).
- If a name exists in some year (file) for one gender only (for example, Female), you will not find that name duplicated for Male with 0 births.
- As I mentioned earlier, the original data for this application is significantly big (almost 323 million baby names), but the data we have are not the individual records of births, instead, it is the births aggregated based on name-sex-year groups.
- The data doesn’t consider people who changed their names. Instead, it reports the name upon baby’s birth date only.
Analysis
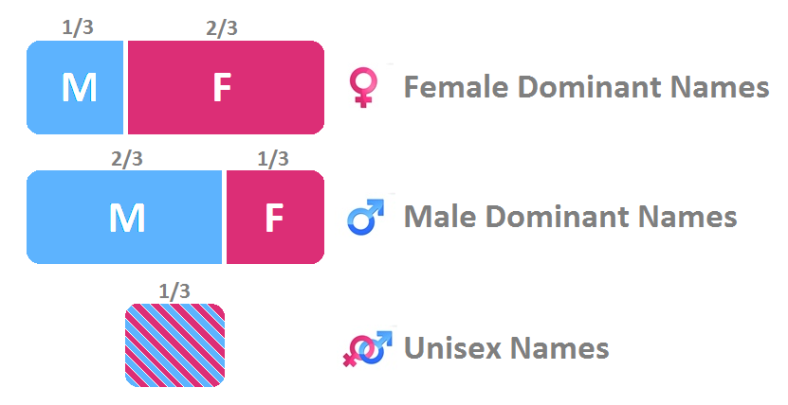
As I mentioned above, I consider the names which are distributed over both genders with one gender percentage within the range from 33.3% to 66.6% as unisex names, so now we need a way to make some data slicing and dicing to get to those names. Try to think about or even write down a few steps to make it before you read on as I am about to spoil it 🙂
So what we need is to get the sweet spot in blue-purple (check the figure below). We need to make a group of all names by name (regardless of the year) and sum its births (for M male/F female from the Sex column). Notice that this analysis is not covering a specific year or decade. Instead, it takes the whole history of names and as far back as we have data (the year 1880).
Here is my approach to get unisex names:
- Put names (name-sex-year-births) in a dataframe.
- Group the dataframe in Step #1 by name.
- Exclude those names with records less than 50 (as we want common names only, if we didn’t make this Step, we could get a name which came up in one year only as 5 girls and 4 boys as a unisex name!)
- Pivot the resultant dataframe to convert the values of Sex column (F, M) into columns and aggregate the births bases on the Sex value.
- Copy the (F, M) columns from the dataframe in the Step #4 into a new dataframe.
- Normalize them there to have the proportion of both genders.
- Add the normalized (F, M) columns to the dataframe you got in Step #4 as new columns (Fprop, Mprop).
- Add a new column total_births, it will hold the sum of the columns (F, M) for every row in the dataframe.
- Exclude those rows with less than 8000 births.
- Subset the DataFrame in Step #9, the criteria for subsetting is applied on rows and it only accepts a row if the proportion of female is between 0.3333 and 0.6666.
As we go through the Steps below, I will keep reminding you where we are.
This python code will take care of Step #1 for us:
# library imports
import numpy as np
import pandas as pd
# initialize variables
all_names = None # main dataframe
names_year_list = [] # empty list
# the years range in the data
years_range = range(1880, 2011)
# a list of the headers of the dataframe we are about to build
cols = ['name', 'sex', 'births']
# loop through the files
for year in years_range:
# file path
file_path = 'names/yob%d.txt' % year
# read the current file into a dataframe
names_year = pd.read_csv(file_path, names=cols)
# add a column with the current year
names_year['year'] = year
# add this dataframe to the list we created above
names_year_list.append(names_year)
# concatenate the dataframe in the list into one dataframe
all_names = pd.concat(names_year_list, ignore_index=True)
Now we have a list of all names grouped by name-year, to get the first 5 rows of this list, type this into your Python command line:
all_names.head()
The result is:
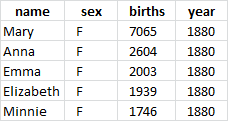
We can read the 1st row as “We had 7065 baby girls named Mary born in the year 1880” and so on…
Moving to Step #2, what was it again? oh yeah, Group the dataframe in Step #1 by name. So let’s do that:
name_gp = all_names.groupby('name');
Yes, it is that easy in the amazing SQL-like Pandas. So now regardless of the Sex and Year columns, group by the name.
The resultant object is of type DataFrameGroupBy, which is not easily accessible as DataFrame object. If you don’t believe me, try to view the first few groups by typing:
name_gp[:5]
#output: TypeError: unhashable type
I will not dive in the cause behind this error, but you may want to know that DataFrameGroupBy objects are of different nature than DataFrame objects, so do not deal with them as they are the same thing. Otherwise, you might get a quite disturbing errors while scratching your head. You might also want to know that many of DataFrameGroupBy object methods such as (apply, aggregate, filter, first, head, last, transform) return a DataFrame object.
Now we get to Step #3, Exclude name groups with records less than 50. As I mentioned above when I enumerated the analysis roadmap, I am doing this Step to extract the common names only, if you like to get ALL unisex names even with few occurrences, skip this Step. So you don’t get shocked if you get different results than mine, remember that the results of this analysis will be presented with this Step included. Here is the code to exclude uncommon names:
names = name_gp.filter(lambda x: len(x) >= 50)
Moving to Step #4, we need to pivot the data to convert the values of the Sex columns (which are M and F) into new columns with the values of births column being aggregated (summed). Need to remind you of table pivot?
names_df = pd.pivot_table(names, values='births', index='name', columns='sex', fill_value=0, aggfunc=sum)
names_df.columns = ['F', 'M']
names_df.reset_index(drop=False, inplace=True)
Notice that in this pivot operation, we sacrificed the year column information, so the summed births values are only related to the name as a key
Why did I suffix this new object with “_gp” because the names within the name column are actually unique, so it feels like we have groups with the name being the key column.
The assignment to columns and resetting the index are just for setting our DataFrame’s headers properly.
Step #5 tells us to Copy the (F, M) columns from the dataframe in the Step #4 into a new dataframe, and here is the code to do it:
tempDF = names_df[['M','F']].copy()
We made this copy to prepare for normalization in Step #6 which is Normalize the columns (F, M) in the copied DataFrame to have the proportion of both genders. I need to emphasise a note here, if you try to normalize them in the same dataframe, the values of columns (M, F) will be overridden. Here is the explanation behind it, we need to keep the absolute values of M, F columns, my reason is that I want to sum them to get an idea about how common a name is compared to other names later. Here is the code to normalize the values within the copied version of the DataFrame:
tempDF = tempDF.div(tempDF.sum(axis=1), axis=0)
This is an efficient use of the methods div and sum, lets divide and conquer to understand it, the code
tempDF.sum(axis=1)
Returns a Pandas.Series object with the sum of the rows of tempDF. which means gets the sum of (F, M) births for every name in the dataframe. Then in the code
tempDF = tempDF.div(tempDF.sum(axis=1), axis=0)
We divide each and every value of tempDF (in both columns F and M) on their corresponding sum (sum of that row, no summing over columns is done here). In the end, we assign the resultant dataframe back to tempDF itself. So for example, if we have a name with 450 boys and 300 gils, we end up with a proportional M value of:
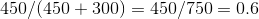
and a proportional F value of:
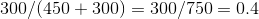
Of course, the proportional values of M and F are (and should always be) equal to 1. Otherwise, you have something wrong with your normalization code.
Now in Step #7, we need to return the proportional values of M and F to the original dataframe from which we copied them. BUT, we should give them new names so we don’t override their original values:
names_df['Fprop'] = tempDF['F']
names_df['Mprop'] = tempDF['M']
let’s get a view of how we are doing now, shall we?
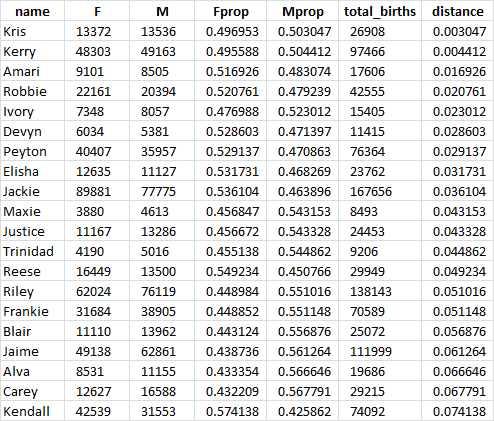
names_df[:5]
Here is the result:
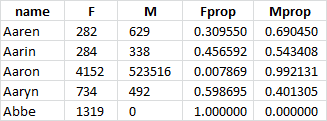
Hmmm… Interesting. We are getting to it, bear with me…
Next, in Step #8 we need to create a new column total_births in which we sum both of M and F columns for every row in the dataframe.
names_df['total_births'] = names_df['M'] + names_df['F']
I’ve added this new column because I want to exclude names with less than 8,000 births, we have data for about 130 years, if a name doesn’t achieve 8,000 births at least, then it is not common, that’s what Step #9 is for. If you want to get ALL unisex names even with only 300 births over 131 years so skip this step.
names_df = names_df[names_df['total_births'] >= 8000]
Moving to Step #10 which is to subset the DataFrame we got from Step #9. This subsetting as mentioned above keeps only those rows with Female proportion between 0.3333 and 0.6666. Notice that we could have done the same thing with Male gender, it doesn’t matter since we only care about the middle third. Here is the final line of code in this analysis:
unisex = names_df[(names_df['Fprop'] >= 0.3333) & (names_df['Fprop'] <= 0.6666)]
Now we have the unisex names in unisex DataFrame.
At first, I wrote this article with sorting the dataframe by the new column total_births descendingly. This was so we get a list of unisex names arranged by popularity. But then I found a better approach, so I will add a new step to the analysis roadmap above:
11. Create a metric derived from the ratio of girls to boys, to indicate how close that name is to be divided equally between both genders, sort by this new metric.
Here is how you do it:
unisex['distance'] = np.abs(unisex['Fprop'] - 0.5)
That means you take the value of Fprop the proportion of girls, subtract 0.5 from it and convert the result into an absolute value, that will get you a value where the closer it is to 0, the closer for its name to be equally divided between genders, that’s why I call this new metric “distance”. We don’t care about which unisex names are used more for girls or boys, we need unisex names, and that’s what we have.
What is left is to sort by our metric distance ascendingly.
unisex = unisex.sort(columns='distance', ascending=True)
Now we have the final list of unisex names, notice that this list is not specific for a decade or this year, but it is for all the data we have (from 1880 to 2010).
unisex[:20]
Voilà! We have the top 20 unisex names
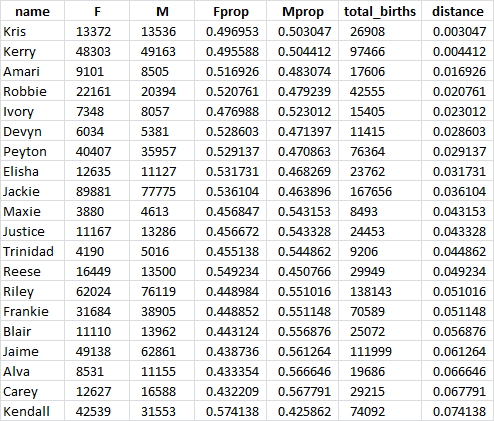
Notice that these unisex names such as Kris and Kerry are not the most common unisex names by popularity but they are the closest names to be equally divided among boys and girls, that’s why they top the list.
Plotting Names
For us to make sure that our analysis is correct, it would be both fun and beneficial to plot some names from the unisex names list. Keep in mind that we cannot plot the names from the unisex dataframe as it doesn’t have the births per year data but we have already used it to know the names of interest to plot, so we can plot them from a different dataframe:
name_year_gp = pd.pivot_table(names, values='births', index=['name', 'year'], columns='sex', fill_value=0, aggfunc=sum)
name_year_gp.columns = ['F', 'M']
name_year_gp.reset_index(drop=False, inplace=True)
Notice that in this dataframe we kept the yearly births. This is a compatible dataframe from which we can plot.
let’s plot the 1st unisex name “Kris”:
plotName(name_year_gp, 'Kris')
# you can find the code of the function plotName below
Here is the resultant plot:
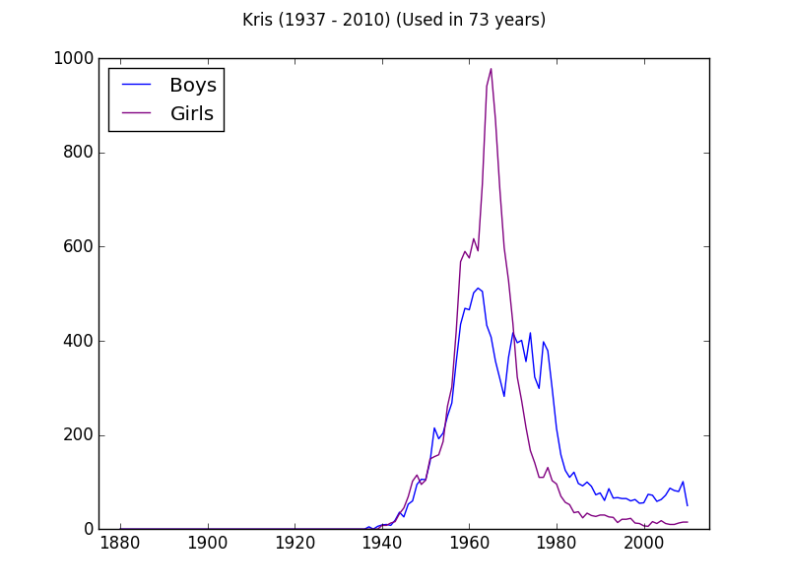
Interesting huh? The name Kris has witnessed a fierce competition between boys and girls over the years, only then to drop for both.
Here is the code of the function plotName used above:
def plotName(df, vName):
from matplotlib import pyplot as plt
min_year = df[df['name']==vName]['year'].min()
max_year = df[df['name']==vName]['year'].max()
name_used = df[df['name']==vName]['year'].count()
x = range(1880, 2011)
m = pd.Series(index = x, data = 0)
m[df[df['name'] == vName]['year']] = df[df['name'] == vName]['M'].values
f = pd.Series(index = x, data = 0)
f[df[df['name'] == vName]['year']] = df[df['name'] == vName]['F'].values
x = np.array(x)
plt.plot(m.index, m.values, color='blue')
plt.plot(f.index, f.values, color='purple')
plt.xlim(1875, 2015)
plt.suptitle("{} ({} - {}) (Used in {} years)".format(vName, min_year, max_year, name_used))
plt.legend(["Boys", "Girls"], loc="upper left")
plt.show()
Here are other four unisex names, I encourage you to plot some other uni-sex names of your choice.
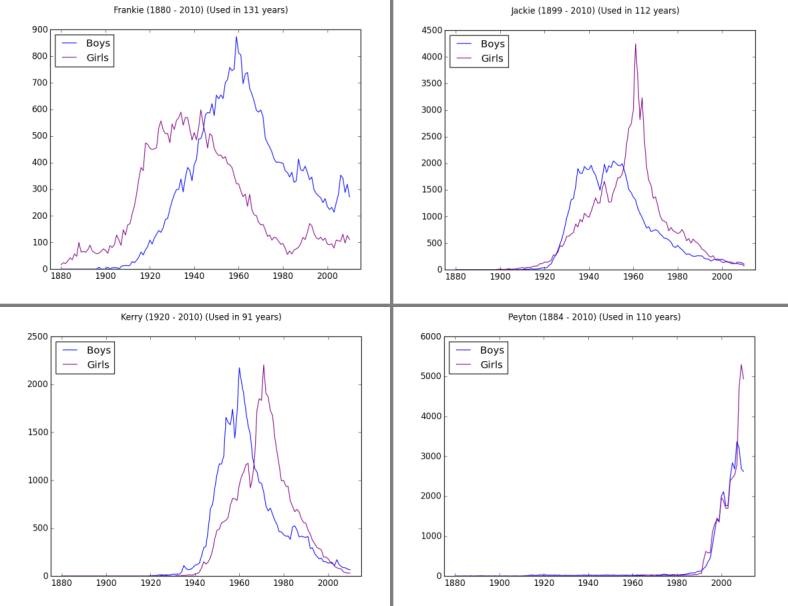
As you can see, obviously, these names are unisex. Data do not lie…
Conclusion
If you enjoyed this data analysis use case, I would be very grateful if you would help it spread by emailing it to a friend, or sharing it on Twitter or Facebook. Thank you!
Keep an eye for the next post, an advanced data analysis where I will give you a good challenge to improve your data analysis skills.