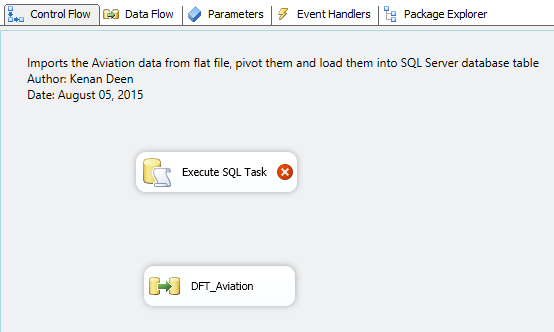
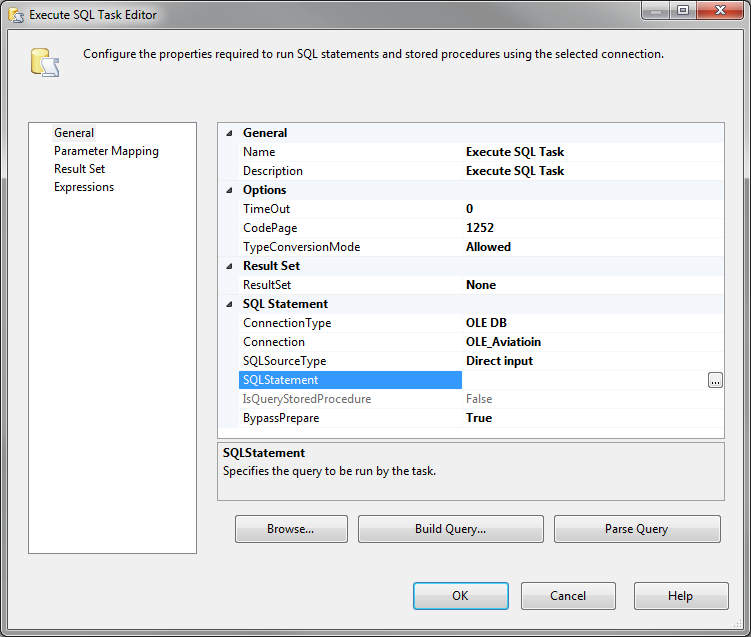
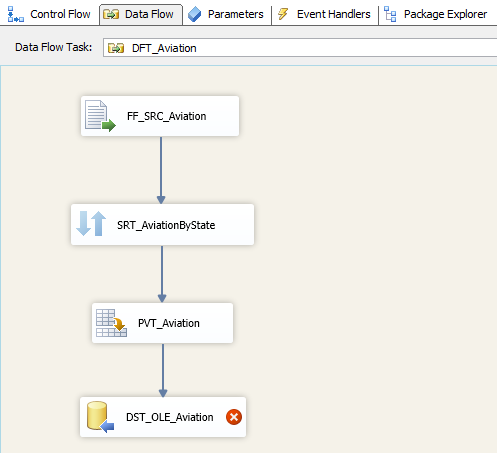
I think you are familiar with the old puzzle of Tower of Hanoi, if not then you can read about it in wikipedia and you can actually play it here. So long story short, it was invented in the year 1883 and it consists of 3 rods and a number of sequentially-sized disks allocated on the leftmost rod, and the objective is to move all the disks from the leftmost rod to the rightmost one with the least possible number of moves. Two important rules you have to follow are that you can only move one disk at a time, and also you can’t move a bigger disk on top of a smaller one i.e. in any rod, the order of disks must always be from the largest disk at the bottom to the smallest disk at the top as depicted in this picture.

There are many algorithms used to solve the Tower of Hanoi puzzle but since puzzles/games have extremely efficient demonstration capabilities of machine learning techniques due to their immediate visual effect and (usually) clear logical workflow, in this post, I present how to take advantage of reinforcement learning techniques to let your program explores and solves Tower of Hanoi puzzle and finally, providing the shortest possible path to the final (winning) state. Tower of Hanoi puzzle solution is considered a deterministic Markov Decision Process.
I will demonstrate the example with 3 disks, but the algorithm is dynamic and can take up to as many disks as you want but you have to take into account the processing power and computational complexity of high number of disks.
I quote from Wikipedia:
The puzzle was invented by the FrenchmathematicianÉdouard Lucas in 1883. There is a story about an Indian temple in Kashi Vishwanath which contains a large room with three time-worn posts in it surrounded by 64 golden disks. Brahmin priests, acting out the command of an ancient prophecy, have been moving these disks, in accordance with the immutable rules of the Brahma, since that time. The puzzle is therefore also known as the Tower of Brahma puzzle. According to the legend, when the last move of the puzzle will be completed, the world will end.[2] It is not clear whether Lucas invented this legend or was inspired by it.
If the legend were true, and if the priests were able to move disks at a rate of one per second, using the smallest number of moves, it would take them 264−1 seconds or roughly 585 billion years[3] or 18,446,744,073,709,551,615 turns to finish, or about 127 times the current age of the sun.
So even if the implemented algorithm is highly optimized, it is totally normal for Tower of Hanoi to take considerably long time for calculating the optimal shortest path.
Here is all the possible states of Tower of Hanoi with three disks:
The total number of all possible states in Tower of Hanoi puzzle is 3 raised to power of the number of disks.

where:
 is the number of elements in the set States, and
is the number of elements in the set States, and
 is the number of disks
is the number of disks
So in our example we have (3 x 3 x 3 = 27) unique possible states of the distribution of disks over the three rods including empty rods but two empty rods can be in a state at max. Here is all the actions possible to move from one state to another.
The least possible number of moves for this puzzle is:
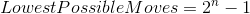
where is the number of disks.
So for a puzzle with 3 disks, the least possible moves count is 7, let’s see if this is achieved in my algorithm below.
I’ve implemented the reinforcement learning algorithm in C# and you can find the full solution files here. I’ve even made it through object-oriented design, here is the classes:
Program: main entry point of the program.
TowerOfHanoi: Defines the basic structure of the game, actually we have only one variable which is the number of disks whereas the number of rods is always three.
StateGenerator: As the name suggests, this class generates the next possible states for an input state, and can be used recursively to generate all the possible states of Tower Of Hanoi with any number of disks. This class has the following public methods:
- GenerateStates: it is used to generate all possible states using a private recursive method GetNextStates
- StateActionMapping: it is used to fill R matrix with the possible actions for each state. It makes use of the non-recursive version of the method GetNextStates to retrieve the direct next steps.
QLearning: Carries the actual implementation of the Q-Learning algorithm which is in short:
Q-Learning is a model-free reinforcement learning technique. Specifically, Q-learning can be used to find an optimal action-selection policy for any given (finite) Markov decision process (MDP).
In Q-Learning algorithm, we have the following variables to use:
- Q Matrix: a 2D array which, at first, populated with a fixed value for all elements (usually 0). It is used to hold the calculated policy overall states i.e. for every state, holds the rewards for the respective possible actions.
- R Matrix: a 2D array which hold the initial rewards, and also I use it to allow the program to determine the list of possible actions for a specific state.
- Discount Factor: Determines the policy of the agent in how it looks to rewards. A discount factor close to 0 will make the agent greedy by only considering current rewards, while a discount factor approaching 1 will make it more strategic and far-sighted for better reward on the long run.
This class has the following methods:
- Constructor: sets some variables.
- Init: calls for generation of all possible states and for the start of the learning process.
- Learn: has the sequential steps for the learning process.
- InitRMatrix: Initializes the Reward matrix and in my implementation of the algorithm, the elements of R could take one of these values:
- 0: It means that we do NOT have information about the reward when taking this action in this state.
- -1: It means that there is no way to take this action in this state.
- 100: It means this is our big reward in the final state where we want to go.
- InitQMatrix: Basically sets all Q elements to 0.0
- TrainQMatrix: Contains the actual iterative value update rule of the Q matrix, and when it finishes execution we expect to have a “trained” agent.
- NormalizeQMatrix: Normalizes the values of the Q matrix making them percentages.
- Test: Provides textual input from the user and printing the optimal shortest path to solve the puzzle.
Utility: a utility class for math functions.
Q Learning Algorithm:
This is the iterative value update rule

and here is the code for the method TrainQMatrix which includes the Q Learning algorithm logic:
private void TrainQMatrix(int _StatesMaxCount)
{
// list of available actions (will be based on R matrix which
// contains the allowed next actions starting from some state as 0 values in the array)
List<int> nextActions = new List<int>();
int nextStep = -1;
int counter = 0;
int init = -1;
int rIndex = 0;
// _StatesMaxCount is the number of all possible states of a puzzle
// from my experience with this application, 3 times the number
// of all possible moves has enough episodes to train Q matrix
while (counter < 3 * _StatesMaxCount)
{
init = Utility.GetRandomNumber(0, _StatesMaxCount);
do
{
// get available actions
nextActions = GetNextActions(_StatesMaxCount, init);
// Choose any action out of the available actions randomly
nextStep = Utility.GetRandomNumber(0, nextActions.Count);
nextStep = nextActions[nextStep];
// get available actions
nextActions = GetNextActions(_StatesMaxCount, nextStep);
// set the index of the action to take from this state
for (int i = 0; i < 3; i++)
{
if (R[init, i, 1] == nextStep)
rIndex = i;
}
// this is the value iteration update rule
// discount factor is 0.8
Q[init, nextStep] = R[init, rIndex, 0] + 0.8 * Utility.GetMax(Q, nextStep, nextActions);
// set the next step as the current step
init = nextStep;
} while (init != FinalStateIndex);
counter++;
}
}
The code is explained with comments, if you still need help, drop a comment below.
Keep in your mind that not training the Q matrix enough could result in the algorithm taking non-optimal paths even if it gets to the final state.
Demo
Here is a demonstration for the algorithm solving the puzzle with 3 disks. Yes I know it is on console but it can be easily linked to UI elements (Windows, web…etc.) later.
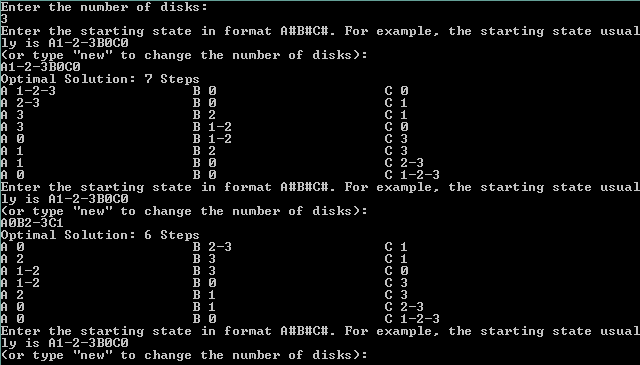
Tower of Hanoi Demo (3 Disks) – Reinforcement Learning
The starting state for the puzzle with 3 disks is “A1-2-3B0C0” which means that all the disks are in the leftmost rod (A) and both of (B) and (C) are empty. You can see that from the starting state, it took the algorithm 7 moves to get to the final state.
Here is another demonstration for the puzzle with 4 disks

Tower of Hanoi Demo (4 Disks) – Reinforcement Learning
The least possible moves count here is 15 which, again, complies with our Least Possible Moves equation above.
I hope you learned something new from this post, please share it on Facebook, Twitter or your favorite social network. As usual, your comments, inquires or corrections are always welcome.